



Blue/Green Deployments: The New Norm for MySQL Upgrades and Schema Changes
MySQL 5.7 Upgrades Got You Seeing Red? It's Time to Think Blue/Green!

If you’ve ever made schema changes on large tables you know that these changes can take some time, use a lot of cpu and often cause production outages. Some schema changes will impact production workloads for the duration of the change as well.
I’m going to demonstrate how to use AWS RDS for MySQL’s Blue/Green feature to make a schema change, migrate from 5.7.43 → 8.0.34 and keep the availability as high as possible. I’ve recently helped several businesses evaluate their 5.7→8.0 upgrade paths as the EOL for 5.7 on RDS is mid-September 2023 approaching quickly on December 2023 February 29th 2024. I’ve recommended and tested this style of migration successfully over the last few months and I wanted to raise awareness for the success that I’ve been able bring to others. Please note, if you’re using MySQL in AWS, you should really be looking into Aurora MySQL instead of RDS MySQL. The flexibility, durability and resiliency options in Aurora far out weigh what’s possible in RDS and given proper architecture and design patterns for your data, you’re most likely to have a better experience - check out my Session at the AWS ANZ Summit 2023 for more information about how Aurora works under the hood to keep resiliency at its best:
Building the Testing Environment
Lets start with my initial configuration.
I’m beginning with a MySQL database on version 5.7.43 with a instance identifier “old-busted”. It’s a very respectable db.t3.micro (Hey I’m frugal, but this will work on any instance family and size) with 20GB of GP2 storage (say frugal one more time and I swear..). I’m going to use the default parameter group and name the database “testing” with a default user of admin and a password so weak that a Commodore 64 could brute force it in less than a minute that I had my password manager create. While that RDS MySQL instance is creating, lets spin up an EC2 instance.

Again, we’re going with Free Tier eligible instances and I’ve made the executive decision to use Graviton - so t4g.small, 30GB GP2 storage, a new Key Pair and a locked down security group to my home IP. I’m going simple here and put a public IPv4 address directly on the host. Please don’t do this in production - there are much better ways.

Now I just install a few of my favorite packages…
Tmux on terminals, htop's dynamic views, Python scripts running, a coder's best news, Packages in Linux, tied up with string, These are a few of my favorite things. MySQL in databases, Node.js in servers, Swift Git commits, no room for reverses, Docker containers like birds on the wing, These are a few of my favorite things. SSH key pairings and Nginx's might, Bash scripting under the soft server light, Vim and Emacs, the joy that they bring, These are a few of my favorite things.
Home sweet home
Lets check the connection to the RDS MySQL instance (after remembering to update the database security group to include our EC2 instance which we definitely didn’t forget to do..)
Simple - we’re in. Now lets setup our simulation.
from faker import Faker
from multiprocessing import Process
import mysql.connector
import time
fake = Faker()
def create_insert_commands(start, end, process_number):
# Establish a new connection for each process
cnx = mysql.connector.connect(user='yourusername', password='yourpassword', host='localhost', database='testing')
cursor = cnx.cursor()
invite_data = [] # List to hold the data for all invites
for i in range(start, end):
name = fake.name().replace("'", "\\'") # Generate a fake name
user = fake.user_name() # Generate a fake user name
invite_data.append((name, user))
# Perform the bulk insert every 10000 records
if i % 10000 == 0:
cursor.executemany("INSERT INTO invitations (invite_name, invite_user) VALUES (%s, %s)", invite_data)
cnx.commit()
print(f"Process {process_number}: Inserted records up to {i}")
invite_data = [] # Clear the invite_data list
# Insert any remaining data
if invite_data:
cursor.executemany("INSERT INTO invitations (invite_name, invite_user) VALUES (%s, %s)", invite_data)
cnx.commit()
print(f"Process {process_number}: Finished inserting records")
cursor.close()
cnx.close()
def main():
total_records = 3919483539
processes = 1
records_per_process = total_records // processes
for i in range(processes):
start = i * records_per_process
if i == processes - 1: # If it's the last process, make sure it goes all the way up to total_records
end = total_records
else:
end = start + records_per_process
process = Process(target=create_insert_commands, args=(start, end, i))
process.start()
if __name__ == "__main__":
main()
(sudo yum install mysql-devel python3.9-devel ; sudo yum groupinstall "Development Tools" ; pip install faker; pip instal mysql-connector-python; pip install pymysql)
This is a quick script designed to create a problem for us. We want a simple table with fake data like this:
CREATE TABLE invitations (
invite_number INT AUTO_INCREMENT,
invite_name VARCHAR(255),
invite_user VARCHAR(255),
PRIMARY KEY (invite_number)
);
mysql> describe invitations;
+---------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------+--------------+------+-----+---------+----------------+
| invite_number | int(11) | NO | PRI | NULL | auto_increment |
| invite_name | varchar(255) | YES | | NULL | |
| invite_user | varchar(255) | YES | | NULL | |
+---------------+--------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)The problem we could create with a table like this is to “run out of int’s” and want to switch to “bigint” (you should be using DynamoDB for this use case most likely).
Lets use the fake-data.py script I showed you earlier and give our table some data.
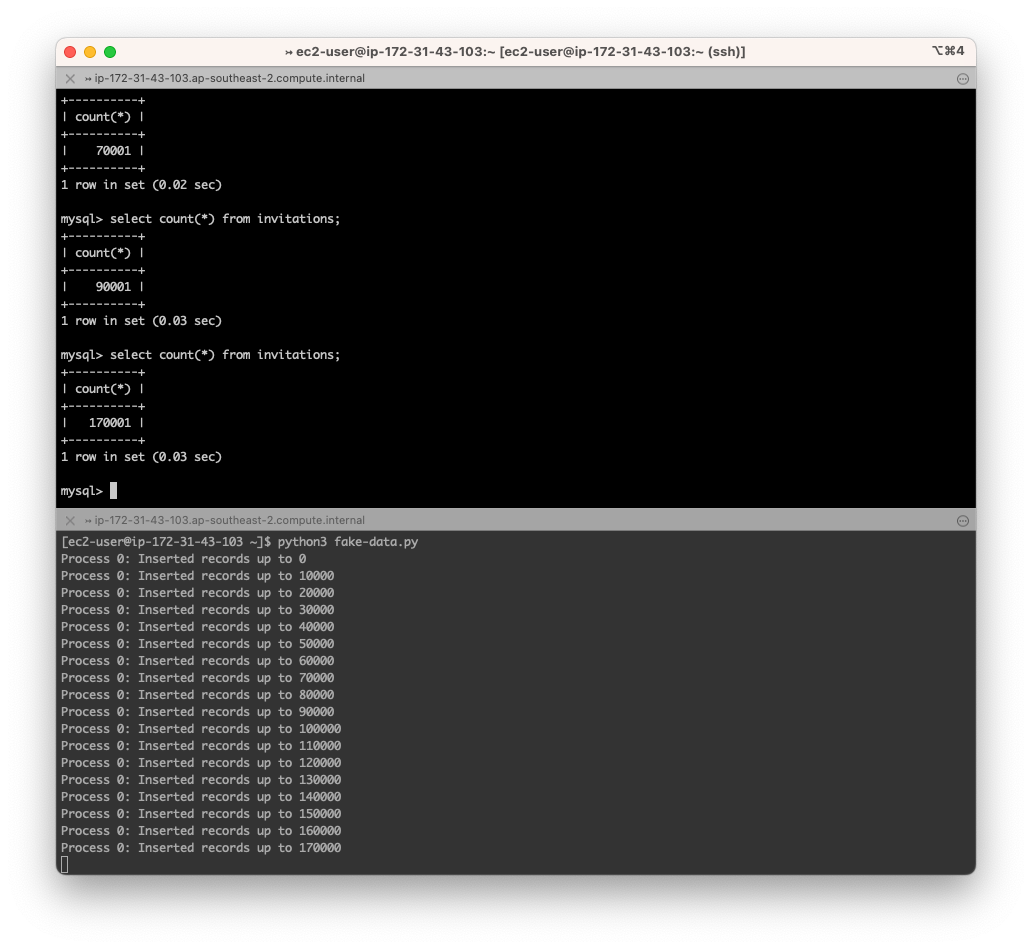
(We don’t actually need to cause the table to run out of integers to finish testing this; its just more fun with some data involved and simulated writes/reads)
Now lets have another script test our connection for us.
import pymysql
import time
import logging
logging.basicConfig(level=logging.INFO)
def connect_to_db():
try:
# Change the parameters based on your MySQL configurations
connection = pymysql.connect(host='yourrdsinstance',
user='admin',
password='password',
db='testing',
charset='utf8mb4',
cursorclass=pymysql.cursors.DictCursor)
return connection
except pymysql.MySQLError as e:
logging.error(f"Error while connecting to MySQL: {e}")
return None
def fetch_latest_row(connection):
try:
with connection.cursor() as cursor:
sql_query = "SELECT * FROM invitations ORDER BY invite_number DESC LIMIT 1"
cursor.execute(sql_query)
latest_row = cursor.fetchone()
connection.commit()
return latest_row
except pymysql.MySQLError as e:
logging.error(f"Error while fetching data from MySQL: {e}")
return None
if __name__ == "__main__":
connection = connect_to_db()
disconnection_time = None
while True:
if connection:
latest_row = fetch_latest_row(connection)
if latest_row:
logging.info(f"Latest row data: {latest_row}")
if disconnection_time:
reconnection_time = time.time()
elapsed_time = reconnection_time - disconnection_time
logging.info(f"Database reconnected. Connection was lost for {elapsed_time:.2f} seconds.")
disconnection_time = None
else:
logging.warning("Failed to fetch latest row. Trying to reconnect.")
connection.close()
connection = None
disconnection_time = time.time()
else:
logging.warning("Connection to database failed. Trying to reconnect.")
connection = connect_to_db()
if not disconnection_time:
disconnection_time = time.time()
# Sleep for 1 second before the next iteration
time.sleep(1)
There we go - now we’re able to monitor the RDS Instance. Let’s test the outage of the instance by having the DB reboot.

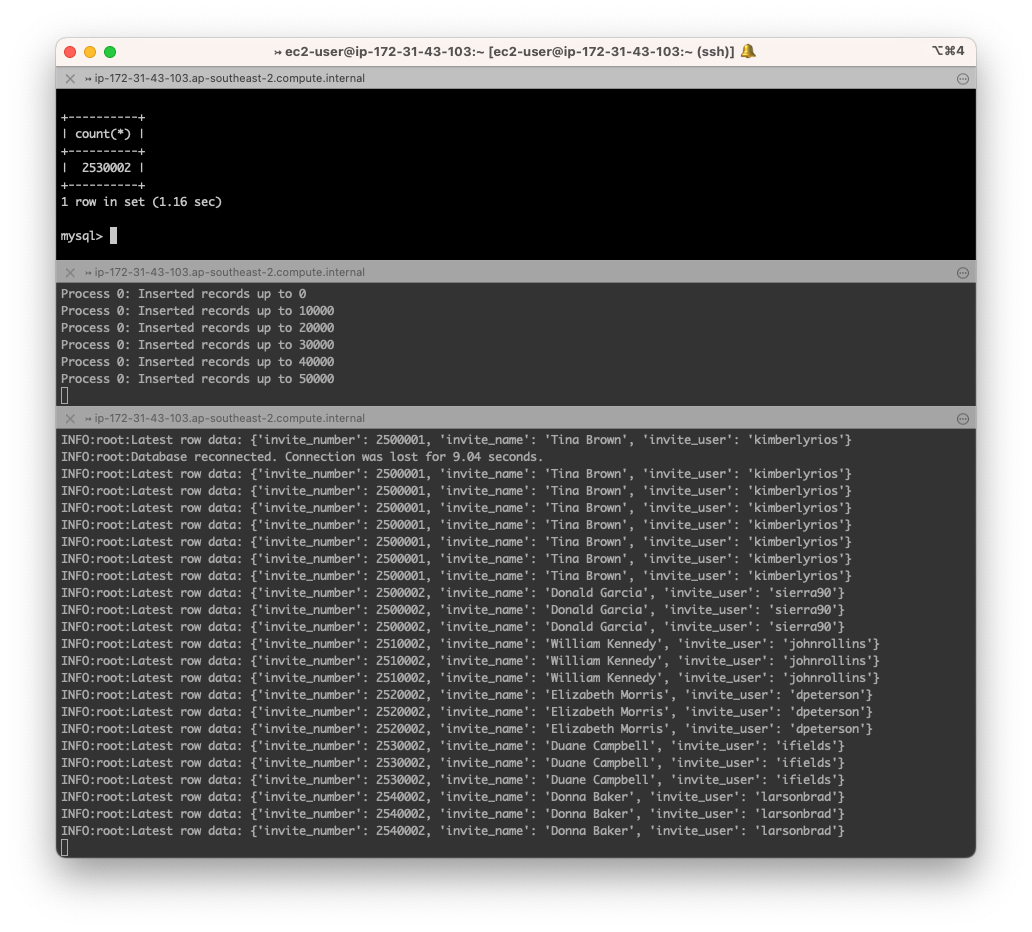
Our DB monitoring script shows that we lost the connection for about 9 seconds ( I did need to start the fake-data.py script again) not bad for a reboot.
Creating the Blue/Green Deployment
Now lets make a Blue/Green Deployment.
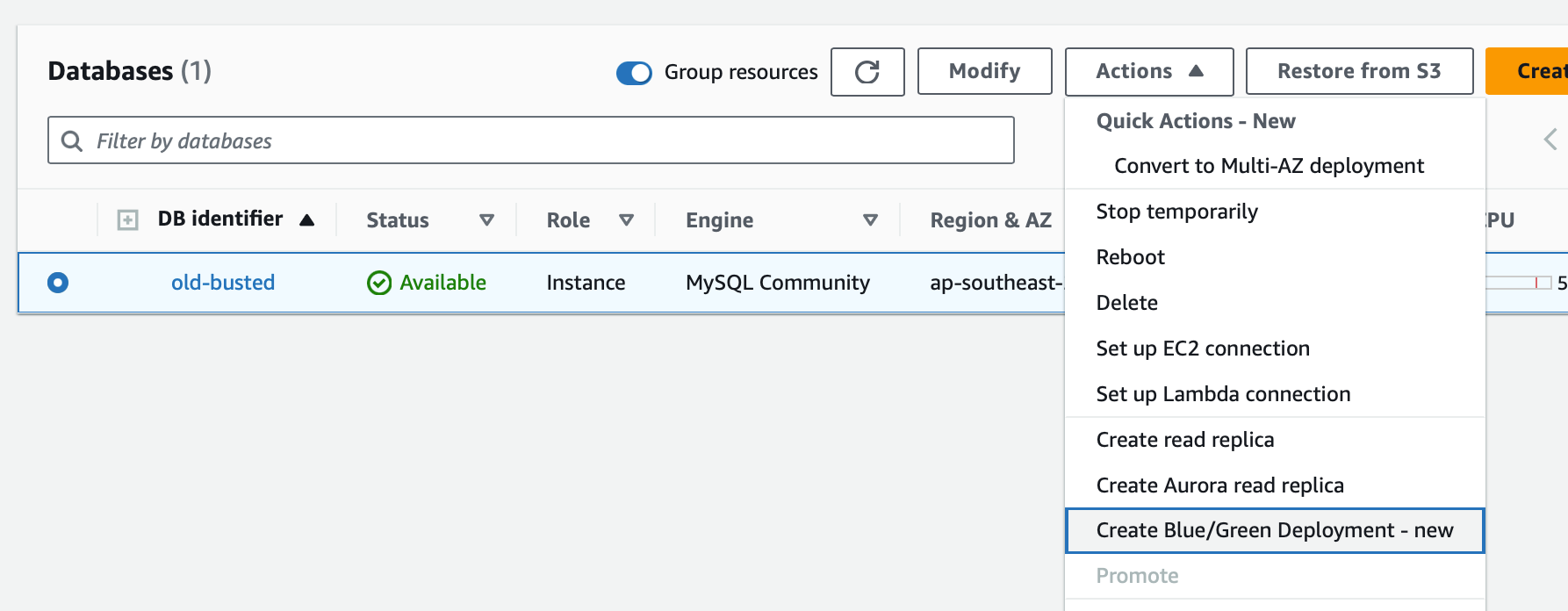
We’ll click create and select MySQL 8.0.34
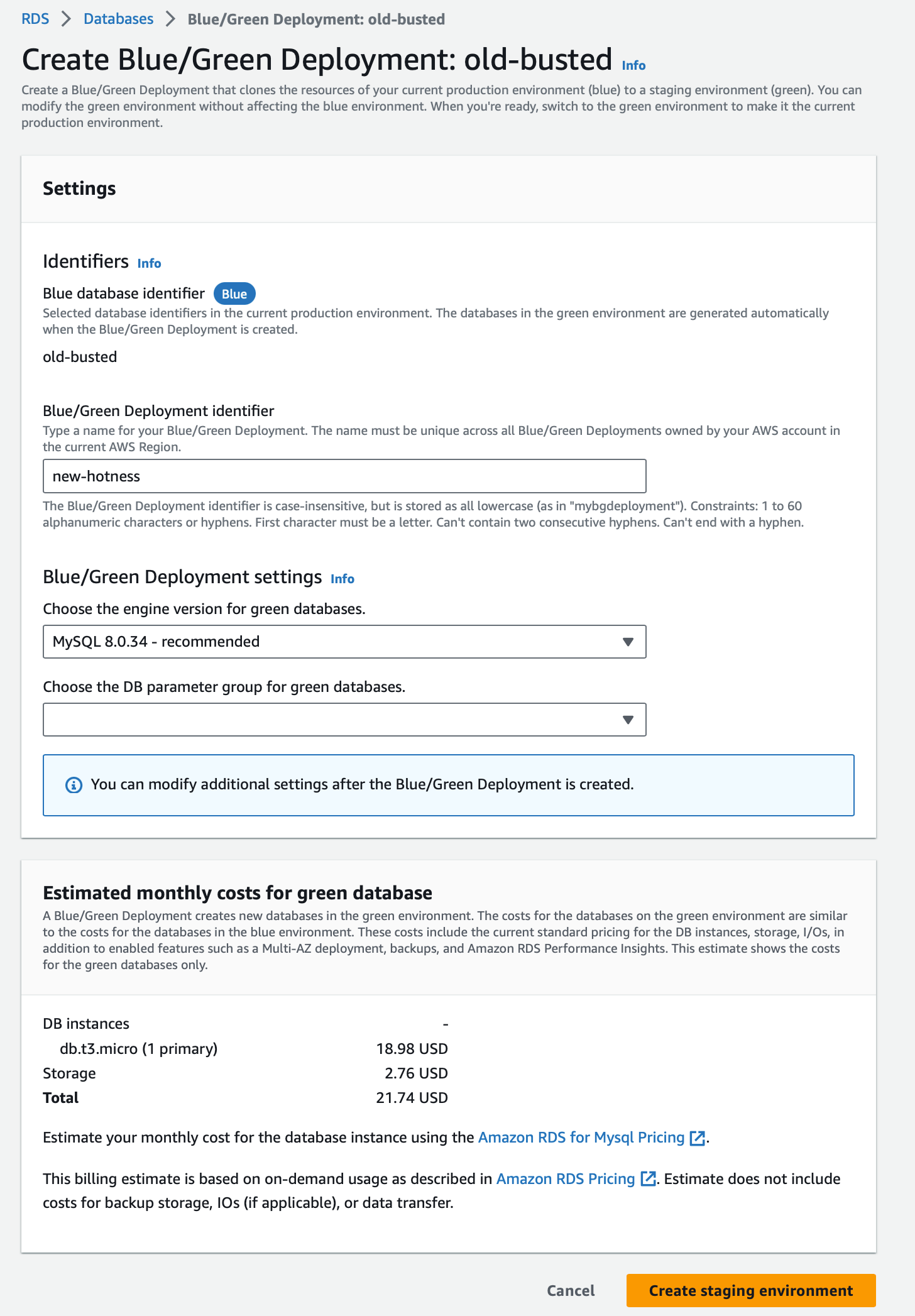
Then we’ll just create the staging environment and wait for it to provision.
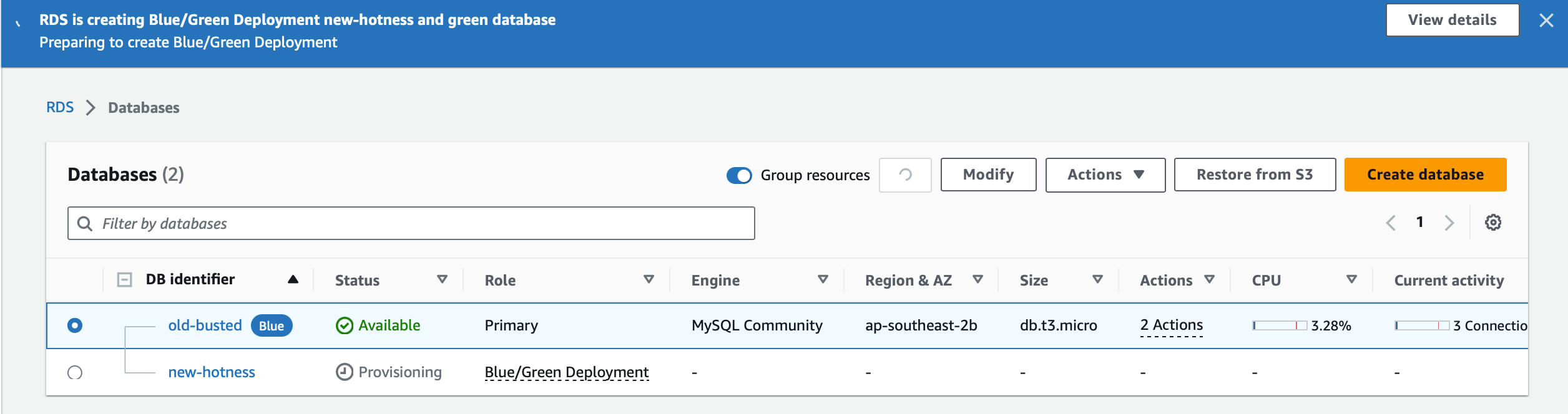
If we had read replicas on old-busted, this will also create new read-replicas in the green side of the “new-hotness” deployment. When we fail over in a blue green deployment in RDS we get to keep our old endpoint names and use our new databases. However we leave our Green environment is what will become our new production “Blue” environment after the switch over.
While we’re waiting, let’s create the parameter group for the Green Instance. I’ll go to the “new-hotness” Blue/Green Deployment and find our Green instance then find the parameter group.
Oh. I don’t have the default mysql-8 parameter group in my parameter group page. Cause I’ve never had a mysql 8 instance in this account before.
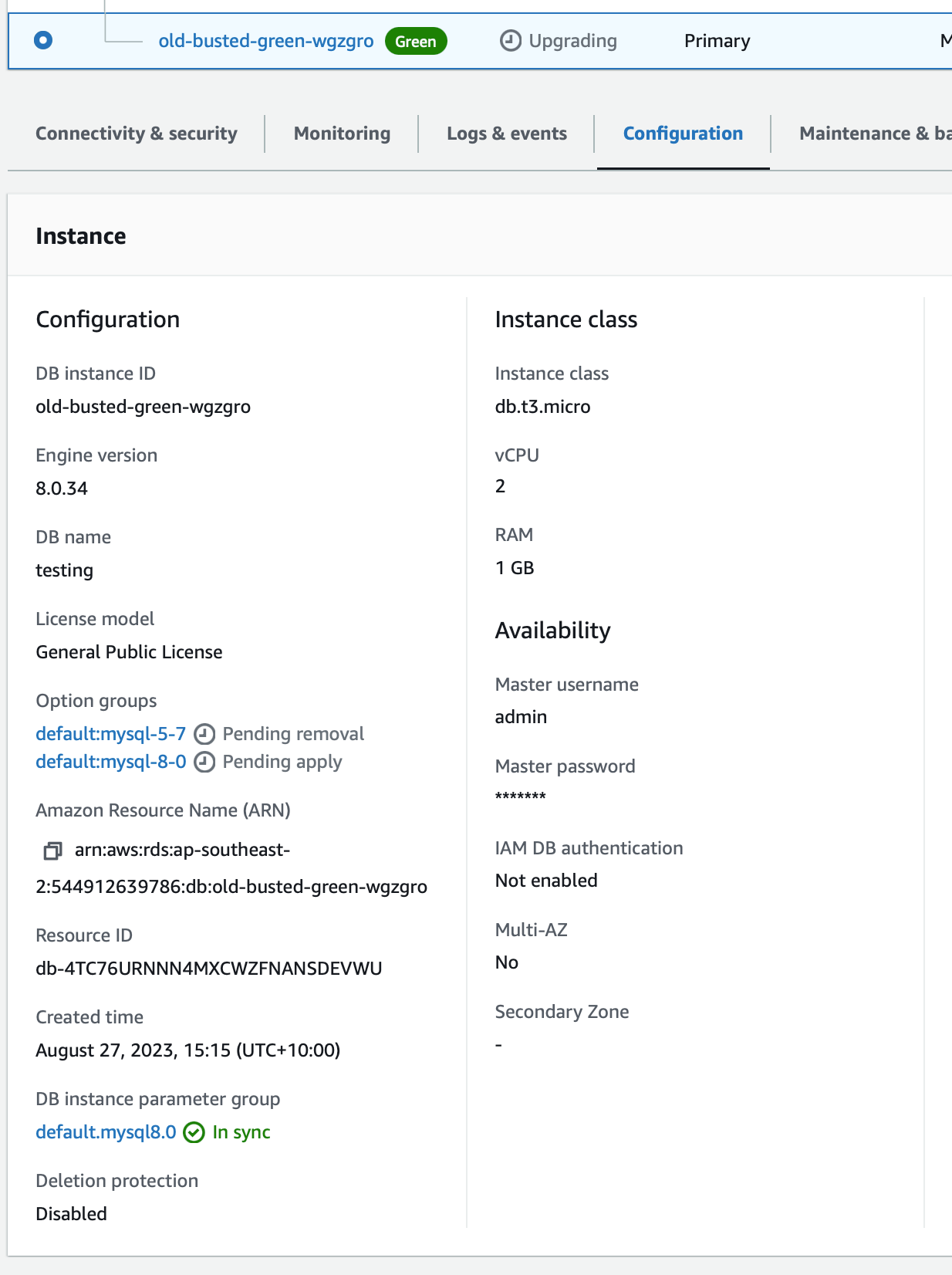
The Green instance will actually start off as a 5.7 instance and then perform an upgrade adding the default:mysql8-0 options and parameter groups! Fun!
Once the 8-0 parameter group is created we need to make a copy of it and then change a single (dangerous) setting.
We’ll start by creating a parameter group like below:
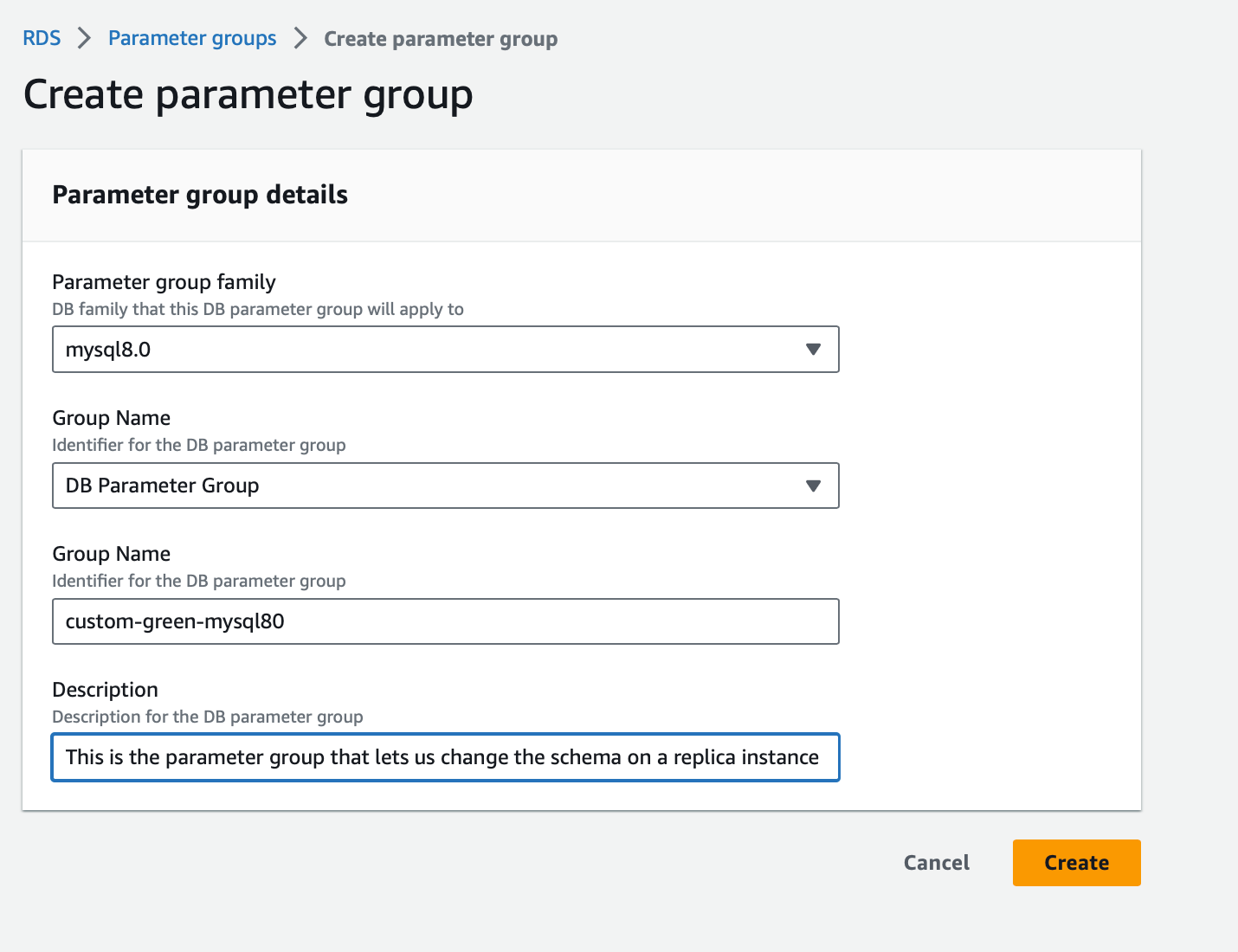
Then we’ll edit the parameter group, we want to change the parameter “read_only” from “{TrueIfReplica}” to “0”

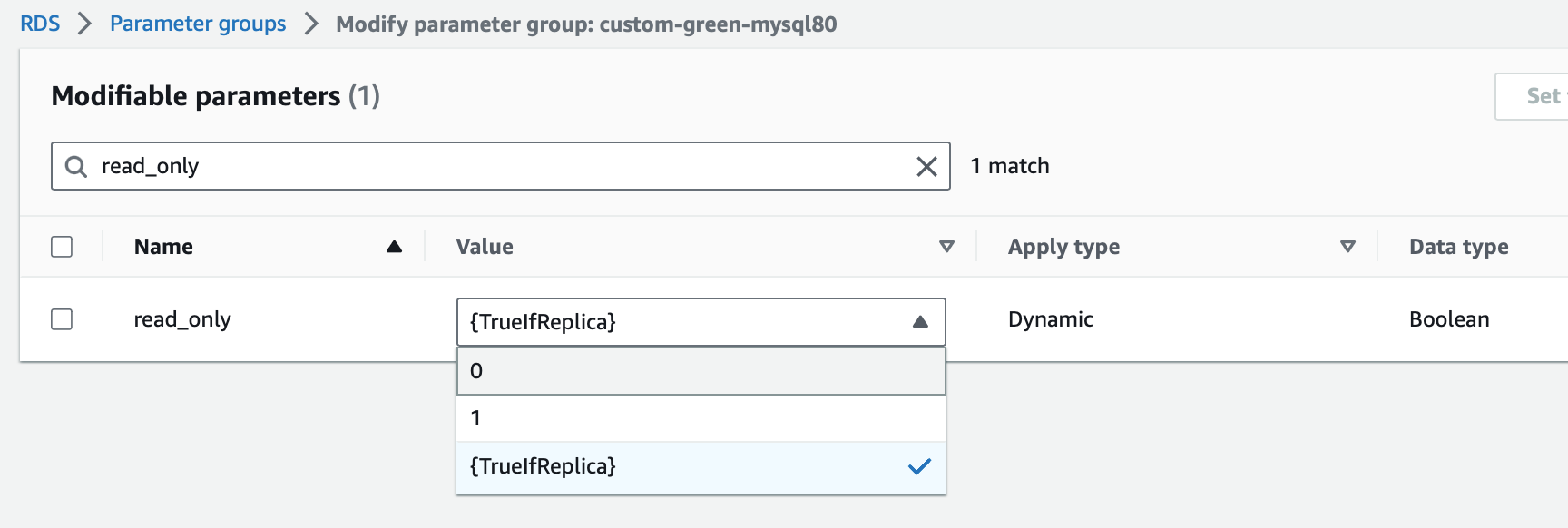
This will allow us to make changes in the Green instance. Please Please know that if you make incompatible changes in the green instance, you will stop replication and you’ll need to sort out the issues before you can make replication work again!
Now that the Blue Green Deployment is created. I’ll assign our new parameter group to the Green instance by modifying it and assigning the custom-green-mysql80 group. Changes to the green database are kept when promoting to blue; however, changes to green do not propagate to blue before the promotion.
Let's wait for the Green instance to finish modifying and take a look at the Deployment itself.

We can see a side by side comparison of our Blue “Active Production” Instance and our Green “Staged Production” Instance. (These databases are offline at the time of publishing, don’t bother trying to DDOS my t3.micro instances at those Endpoints)
We can also see some stats about the instance in the Blue/Green Deployment:

Now that our instances are available and replicating, let’s connect to the green instance and make our schema change! After we definitely remember to reboot the instance first to apply the parameter group changes….
Replication will kick back in after the reboot, don’t worry!
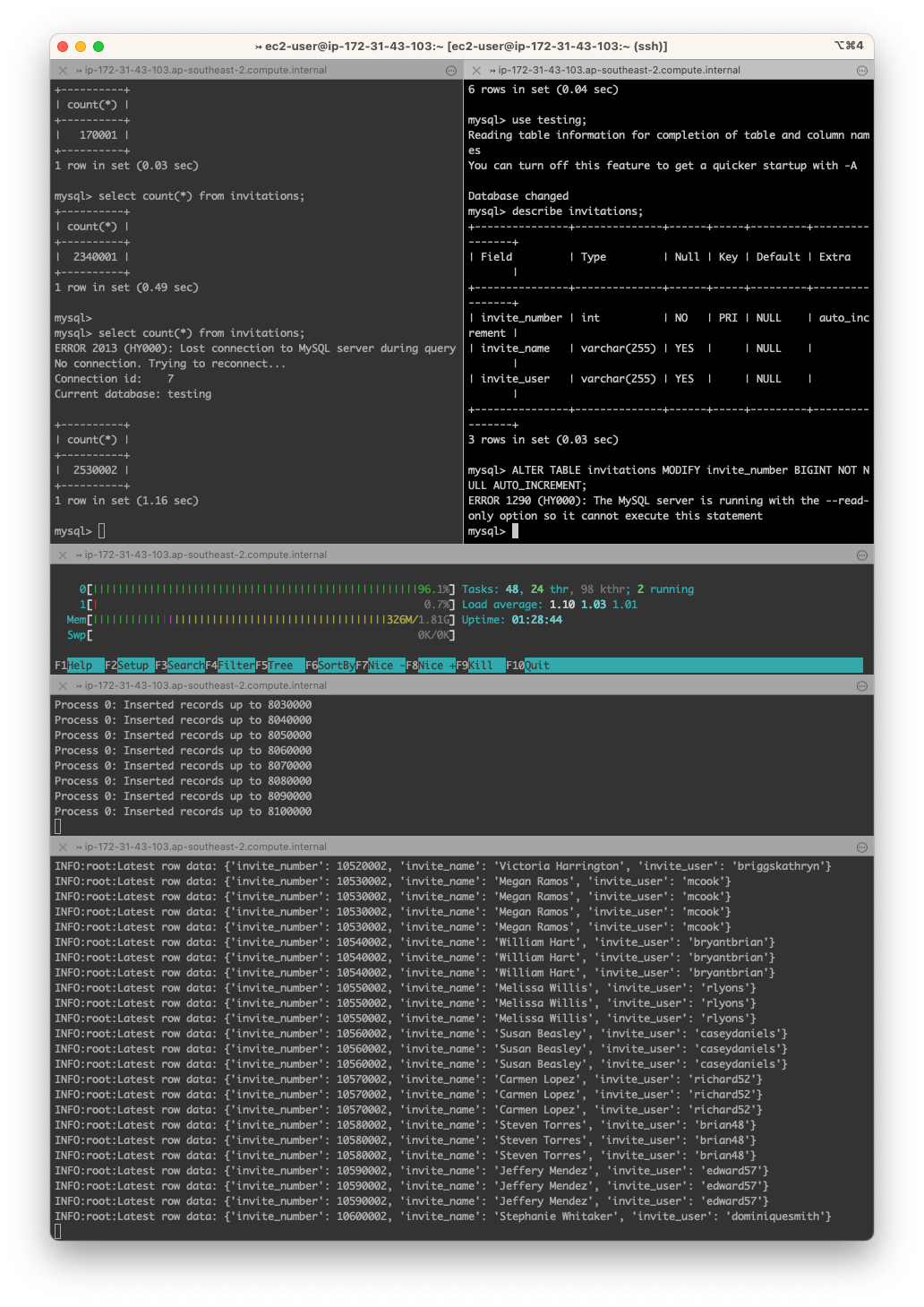
mysql> use testing;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> describe invitations;
+---------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------+--------------+------+-----+---------+----------------+
| invite_number | int | NO | PRI | NULL | auto_increment |
| invite_name | varchar(255) | YES | | NULL | |
| invite_user | varchar(255) | YES | | NULL | |
+---------------+--------------+------+-----+---------+----------------+
3 rows in set (0.03 sec)
mysql>ALTER TABLE invitations MODIFY invite_number BIGINT NOT NULL AUTO_INCREMENT;
Query OK, 11100002 rows affected (50.63 sec)
Records: 11100002 Duplicates: 0 Warnings: 0
mysql> describe invitations;
+---------------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+---------------+--------------+------+-----+---------+----------------+
| invite_number | bigint | NO | PRI | NULL | auto_increment |
| invite_name | varchar(255) | YES | | NULL | |
| invite_user | varchar(255) | YES | | NULL | |
+---------------+--------------+------+-----+---------+----------------+
3 rows in set (0.06 sec)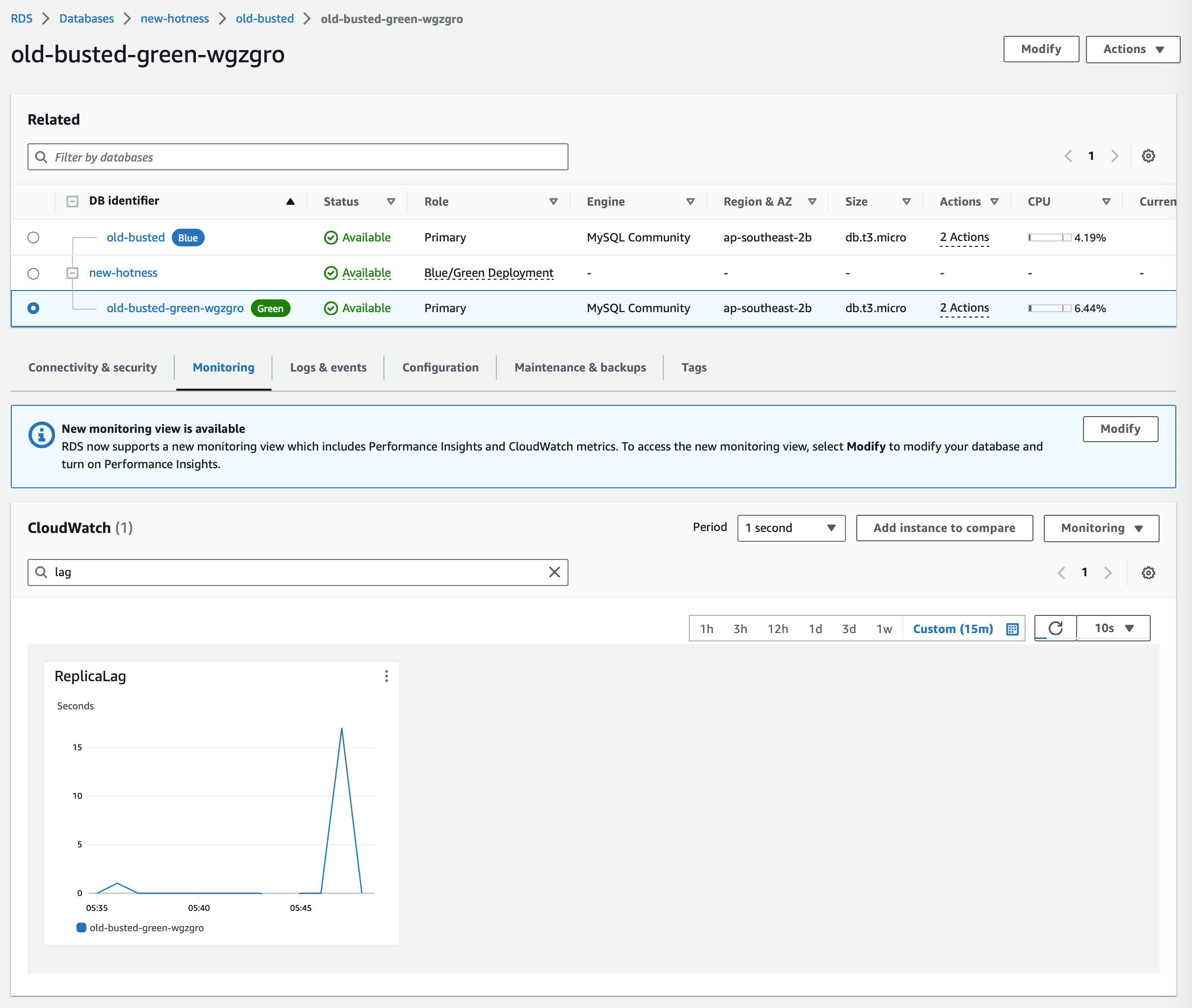
We can see that our Green instance has completed our schema change and is on mysql 8.0! We also induced some replica lag while the schema change was taking place. The amount of replica lag will depend on how big your tables are. If its going to take DAYS to do your schema change here, be wary of how much disk you have available and when you plan your fail over, the replica lag must be near 0 for a switch over to happen.

We should switch to the desired parameter group (the default 8.0 group in this case before our switchover takes place. We wouldn’t want any future read replicas having “write” permissions!
Our Blue instance and Green instance now have our desired changes.
Let’s proceed with the switch over and observe the downtime.
Understanding the Switchover
A few things happen before and during the switch over, you can read all about them here: https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/blue-green-deployments-switching.html but I’ll put a summary in below.
Key Features:
Timeout Setting: You can set a switchover timeout ranging from 30 seconds to one hour. The default is 300 seconds. If the switchover exceeds this limit, all changes are rolled back.
Guardrails: Before initiating a switchover, RDS performs a series of checks on both the blue and green environments to ensure their readiness. These include checks on replication health, replication lag, and active writes. Any discrepancies will halt the switchover.
Switchover Actions: During the switchover, RDS runs guardrail checks, stops new write operations, drops and disallows new connections, waits for replication to sync, and renames DB instances and endpoints in both environments.
Post-Switchover: After a successful switchover, the new production environment allows write operations while the old one allows only read operations until rebooted.
Event Monitoring: Amazon EventBridge can be used to monitor the status of a switchover.
Tagging: Tags configured in the blue environment are transferred to the green environment post-switchover.
Rollback: If the switchover is halted for any reason, all changes are reverted to maintain the integrity of both environments.
Best Practices:
Thoroughly test resources in the green environment.
Monitor CloudWatch metrics.
Identify low-traffic periods for the switchover.
Ensure DB instances in both environments are healthy and available.
Keep DNS cache TTL to a maximum of five seconds.
Complete data loading before switchover.
Note: Modifications to DB instances are not allowed during a switchover.
Performing the Switchover
To perform the switchover we need to select our Blue/Green Deployment in the console and then select “Switch Over” from the actions menu. I have my monitoring script running and I am still inserting records into the table on the Blue endpoint.
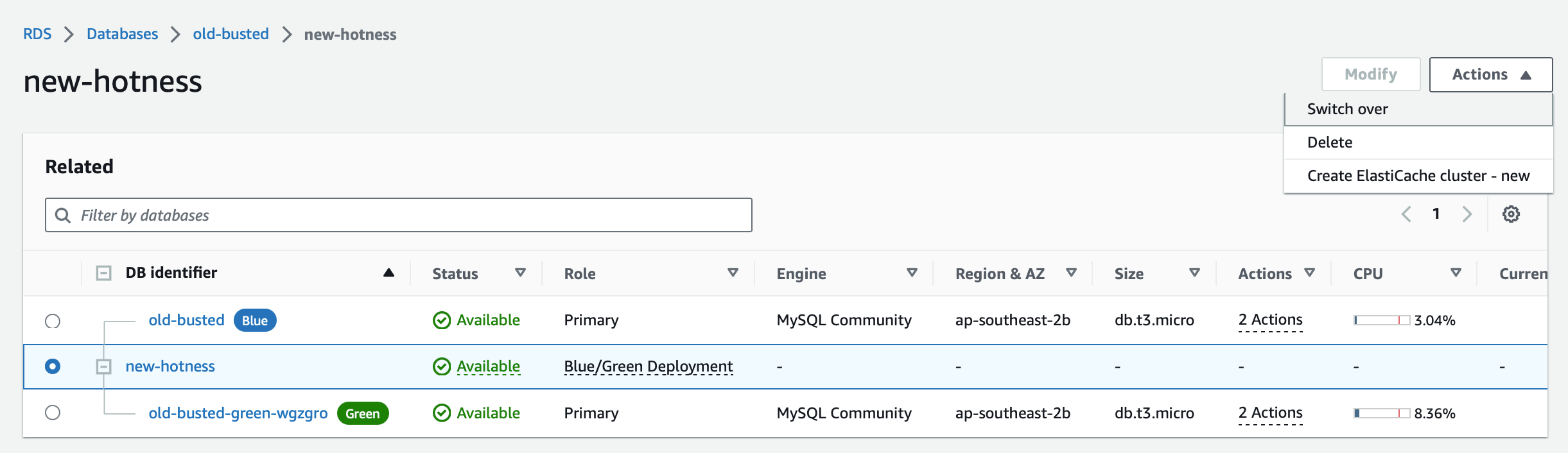
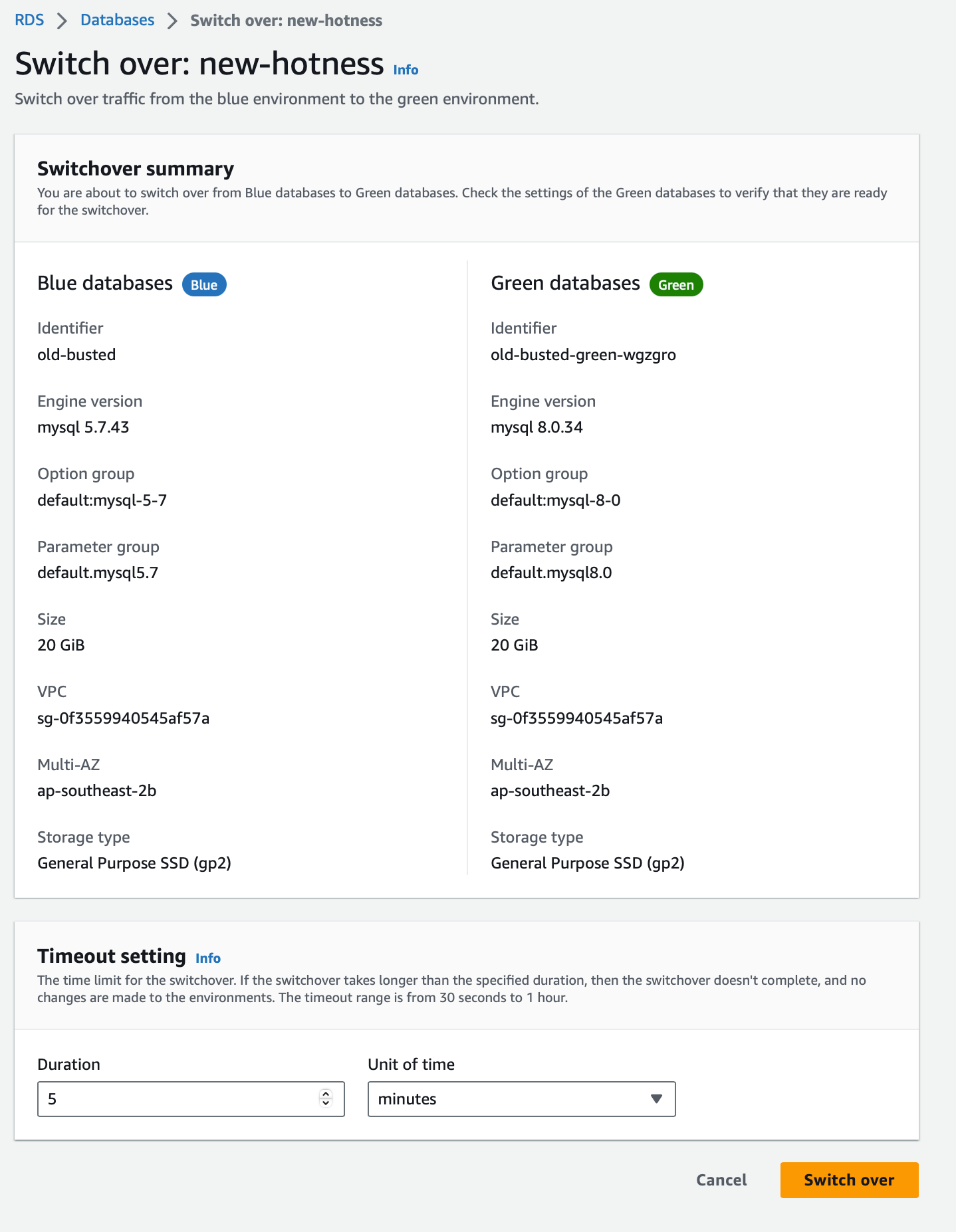
We get an opportunity to review our changes and then we can just click “Switch over”
During the switchover, RDS runs guardrail checks, stops new write operations, drops and disallows new connections, waits for replication to sync, and renames DB instances and endpoints in both environments.
Let’s see how long that takes.
Writes were unavailable in the video from 0:17 → 1:22 for a total of 1:05. Not too shabby. Reads were unavailable from 0:27→ 1:22 for a total of 55seconds. My monitoring script saw about 2 seconds of outage, and due to bugs in the script that I’m not willing to resolve, its missed that its last check was stalled and waited too long for a timeout as the endpoint flipped over to the new instance. At the end I’m left with my production endpoint on 8.0 with my schema changes and my old 5.7 instance renamed to “old-busted-old1” still running 5.7!
Conclusion: Navigating Changes Seamlessly with AWS RDS's Blue/Green Feature
Embarking on database schema changes or version upgrades is often fraught with risks that could affect the availability and performance of your applications. This blog post has been a somewhat comprehensive guide on how to leverage the Blue/Green deployments feature in AWS RDS for MySQL to make these transitions as smooth as possible.
By following this approach, we've been able to update the MySQL version from 5.7.43 to 8.0.34 and alter the database schema—all while maintaining high availability. The Blue/Green feature, with its guardrails and rollback capabilities, ensures that the switchover is as risk-free as possible. Monitoring tools and best practices were also discussed to provide a holistic strategy for database migration and schema modification.
Key Takeaways:
Efficiency: The Blue/Green deployment feature allows you to make schema changes and version upgrades without significant downtime. In our test, the total connection unavailability was just 1 minute and 5 seconds.
Safety Nets: The guardrails and timeout settings are invaluable for preventing unwanted disruptions and data inconsistencies. If something does go wrong, the process rolls back, ensuring data integrity.
Monitoring: Real-time monitoring allows you to keep tabs on the switchover process and quickly react to any issues.
Flexibility: This method is not just for large enterprises but is scalable to any size, as demonstrated using a db.t3.micro instance.
Future-proof: The Blue/Green deployment strategy makes future changes easier to manage and less risky, setting you up for long-term success.
As we near the End-of-Life for MySQL 5.7 on AWS RDS, this strategy offers a solid pathway to upgrade to newer versions. However it's worth considering a move to Aurora MySQL for even more robustness and flexibility, as discussed in my session at the AWS ANZ Summit 2023.
With these tools and strategies in your arsenal, may your databases always be available, and your schema changes forever be smooth!
(Subscribing is Free and Helps me out a ton!)